Point and Interval Estimation
 View on GitHub
View on GitHubStatistical Inference
One of the goals of statistical inference to draw conclusions about a population based on a random sample from the population.
Specifically, we seek to estimate an unknown parameter , say using a single quantity called the point estimate .
The point estimate is obtained using a statistic, which is simply a function of a random sample. The probability distribution of the statistic is its sampling distribution.
Examples of a statistic include:
- sample mean and sample median
- sample variance and sample standard distribution
- sample quantiles
Estimator Variance and Standard Error
The standard error of a statistic is the standard deviation of its sampling distribution
For instance, if observations come from a population with unknown mean and known variance , then and the standard error of is
if the variance of the original population is unknown, then it is estimated by the sample variance and the estimated standard error :
Confidence Interval
For mean When SD is known
Consider a sample from a normal population with known variance and unknown mean . The sample mean is a point estimate of .
The 68-96-99.7 Rule
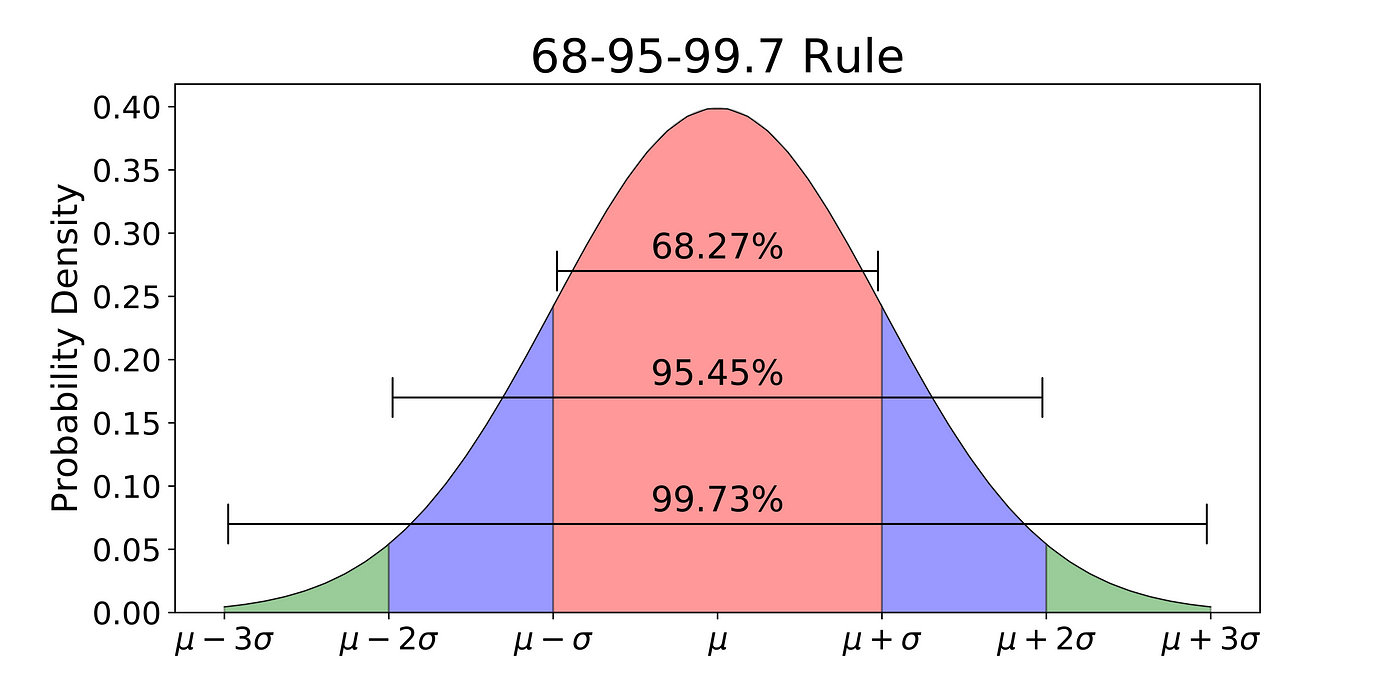
68% of the data is within 1 standard deviation, 95% is within 2 standard deviation, 99.7% is within 3 standard deviations.
The symmetric confidence interval for is
For mean when SD is known (reprise)
Another approach to C.I. building is to specify the proportion of the area under (z) of interest, and then to determine the critical values (the endpoints) of the interval.
For a symmetric 95% confidence interval, we need to find such that .
But the LHS can be re-written as
The confidence level 1 - α is usually expressed in terms of a small α, e.g. α = 0.05 ⇒ 1 - α = 0.95 confidence level.
For α = 0.01, 0.02, . . . , 0.98, 0.99, the corresponding are called the percentiles of the standard normal distribution. In general,
P is the percentile
The symmetric 100(1 - α)% confidence interval can generally be written as:
For a given confidence level α, shorter confidence intervals are better in relation to estimating the mean:
- estimates become better when the sample size n increases;
- estimates become better when σ decreases.
Choice of Sample Size
The error we commit by estimating \mu via the sample mean X is smaller than , with probability 100(1 - α)%.
If we want to control the error, the only thing we can really do is control the sample size:
If σ is known, we know from the CLT that .
If σ is unknown, it can be shown that follows approximately , the Student T-distribution with degrees of freedom.
Consequently, for a confidence level α,
,
Equality is reached if the underlying population is normal.
C.I. for .
Confidence Interval for a Proportion
If (number of successes in trials), then the point estimator for is .
Recall that and .
We can standardize any random variable: is approximately .
To calculate the confidence interval for a proportion:
Summary
Sample: . Objective: predict \mu with confidence level α.
If population is normal with known variance σ2, the exact 100(1-α)% C.I. is .
If population is non-normal with known variance and is ‘big’, the approximate 100(1 - α)% C.I. is .
If population is normal with unknown variance, the exact C.I. is .
If population has unknown variance and n is ‘big’, the approximate C.I. is .