Natural Language Processing
 View on GitHub
View on GitHubNatural language processing (NLP) is an interdisciplinary field at the intersection of computer science, artificial intelligence, and linguistics. NLP is concerned with the interaction between computers and human (natural) languages, and with the processing of textual information for various information-based applications.
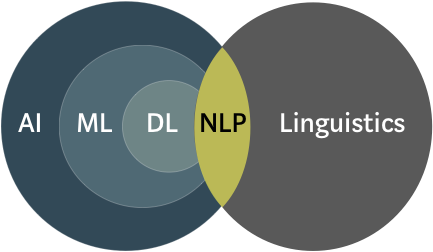
NLP is concerned with linguistic analysis at various level: morphology, syntax, semantics, pragmatics.

Applications
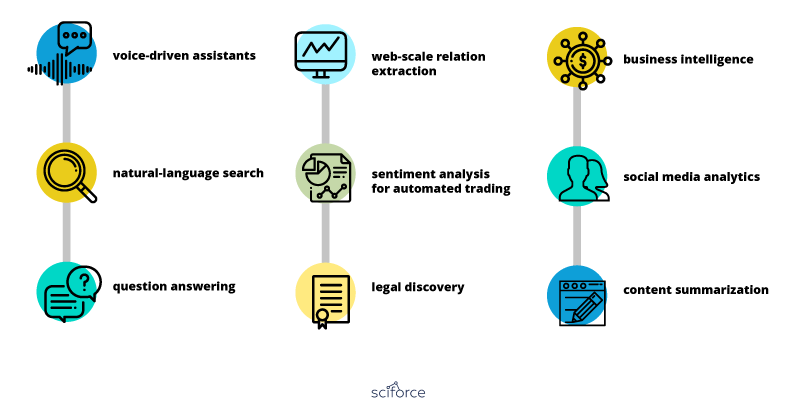
Applications in NLP include text categorization, text summarization, machine translation, sentiment analysis, and question-answering, etc.
Natural Language Understanding (NLU) aims to help computers understand, manipulate and interpret human language. The NLU is at the heart of the increasingly popular dialogue systems.

Linguistic Analysis
- Sentences: breaking up a document into sentences
- Words: breaking up a document into words (where punctuation is a word)
- Lexical Units (compound nouns): breaking up a document into words, but keeping compound nouns together
- Morphology (finding roots): breaking up a document into the roots of a sentence
- Part-of-Speech (Grammatical Category): breaking up a sentence into grammatical features
- Syntactic Analysis Constituency: breaking up a sentence using Part-of-Speech and finding the types of phrases (i.e. Noun, Preposition, Verb)
- Syntactic Analysis Dependencies: breaking up a document using Part-of-Speech and finding the dependencies between them
- Coreference Analysis: Seeing what each subject in a document refers to
Ambiguity
Why is NLP so hard? Because language is AMBIGUOUS. Ambiguity is THE most difficult problem in NLP, and it comes in all flavors and forms.
- Various forms of words
- ex: cell-phone, cellphone, cell phone
- Sentence splitting
- ex: (standard with separators) The A.I. course CSI20.02-7 will be offered in winter 2021.
- ex: (texto) not sure about tonight will check my schedule when I get home
- POS tag
- ex: Will will finally have the will to write his will.

NLP Pipeline
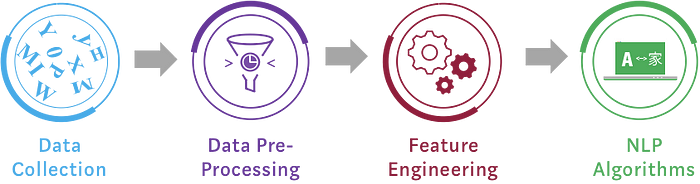
Steps:
- Tokenization: Break it into words
- Lemmatization: Use morphology
- POS tagging
- Sentence segmentation: Break document into sentences
- Constituency or Dependency parsing: Use syntactic analysis constituency and dependencies
Named-entity recognition
A subtask of information extraction that seeks to locate and classify atomic elements in text into predefined categories, such as names of persons, organizations, locations, expressions of times.
Entity types
- Enamex: Person, Org, locations
- Timex: Date, Time
- Numex: Money, Percentage, Quantity
NER Approaches
Regular expressions
- Entities with regular forms (predictable)
- Examples: dates, phone numbers, postal codes, emails
- adaptable to new "formatted" data
- not trivial to write the expressions, requires NE which have a regular surface form structure
- most languages have Regex support
Gazetteers
- Entities with a limited number of instances (enumeration)
- Examples: cities, countries, companies
- easy to have a first working system, many lists exist for various NE and Concepts
- Require additional matching algorithms for typographical errors
- Wikipedia and other resources.
Edit Distance
Calculate the distance between the surface forms.
- Deletion +1
- Insertion +1
- Replacement +1 (or +2 in Levenhstein distance)
Supervised Machine Learning in NLP
Formulate a NLP task as a SML problem
- Think of what is to be predicted
- Yes/No sentence split
- POS tag
- Named Entity
- Obtain ANNOTATED data
- Look for an existing dataset
- Build your own dataset
- Develop/use an annotation platform
- Think of input features
- What COULD be useful in prediction?
- How easy can we get this information?
Word Embeddings
Using a neural network, construct a word representation which encapsulates the word’s predictive nature of its context. A word becomes a vector representation in an N dimensional space, which is called an embedding.
Embedding are inputted into a model through learned weights.