Generative AI
 View on GitHub
View on GitHubGenerative AI refers to programs that can use existing content like text, audio files, or images to create new plausible content.
The MIT Technology review described generative AI as one of the most promising advances in the world of AI in the past decade. Generative AI enables computers to learn the underlying pattern related to the input, and then use that to generate similar content.
Applications of Generative AI include:
- Music generation
- automatically generate music (in the style of some example)
- Fashion Design
- create a new fashion style, or a personal fashion item
- Image/Video compression
- Expensive to store photos, could retrieved a compressed version
- Voice generation
- Pharmaceutical Drug Discovery
- Explore molecules, biomarkers and proteins to discover combinations/mutations
Probabilistic Models
Generative models include Naive Bayes, whereas Discriminative Models include SVM, MLP.
Language Model
Unigram model
Learning from a very large corpus, calculate the probability of each word. Generate words based on their probability.
Bigram model
Learning from a very large corpus, calculate the probability of each word following another word. Generate words based on their conditional probability to the previous word.
You can do the same with a tri, quad and so on gram model.
A more complex n-gram model will generate more realistic text. But the models get very big:
- in theory, the model is of size with being the size of the vocabulary and the size of the n-gram
- in practice, much smaller ("sparse") models are used
Important to calculate the probabilities on texts of the same style as what you want to generate.
Latent Spaces and Auto-Encoders
Representation
Images can be composed of several attributes. For example if we're describing 3-D shapes then we can use:
- height
- radius
- orientation
- color
Is it possible to learn these sort of features?
Latent Representation
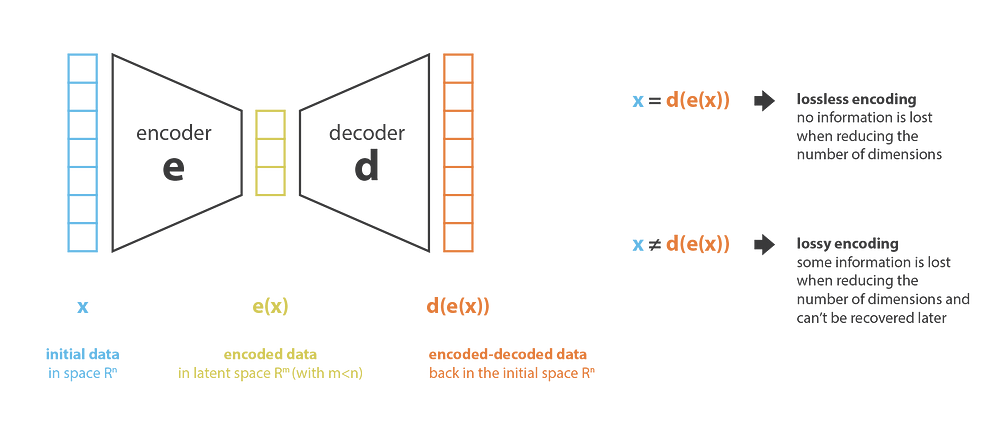
Latent representation is a compressed image.
Can we encode an image in a way that when it goes through a neural network, which can produce the same image as an output?
Auto-Encoders
Code that is generated using an auto encoder is called a Learned code and this is also called a Latent Representation
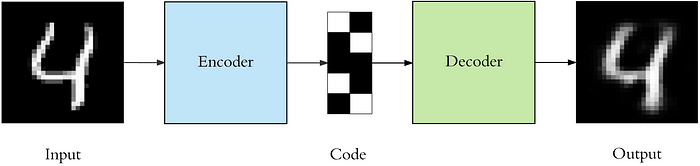
This illustrates how images are coded:
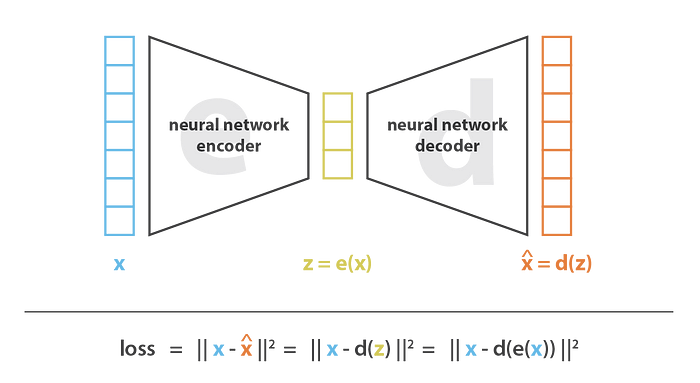
Training of Auto-Encoders
Define an error function -> L2 error. Train the network with Gradient Descent Algorithm using back-propagation.
- Initialize weights at random
- Repeat
- For each example in the training set:
- Predict (forward pass)
- For each weight
- Calculate derivate of error
- Update weight
- For each example in the training set:
- Until "done"
- Fixed number of iterations
- Error < error threshold
- < change threshold
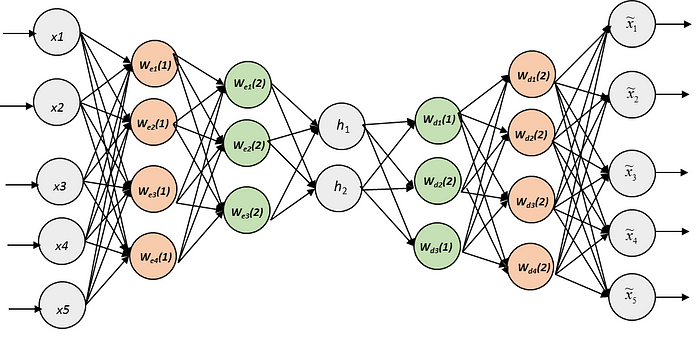
Latent Space
If I have to describe latent space in one sentence, it simply means a representation of compressed data.
Generation by Interpolation
Use the latent space for generation. For example if you wish to generate a new sample halfway between two samples, just find the difference between their mean () vectors, and add half the difference to the original and then simply decode it.
Generation by Finding Vectors for Features
For example, for the generation of glasses on a face, it is necessary to use two samples, one with glasses, the other without. We must then calculate the difference between the latent representations of these two samples. This difference becomes a vector "glasses" which can be added to any other latent representation (that of another face).
Generative Adversarial Networks (GANS)
GANs are deep neural net architectures comprised of two neural networks, competing one agains the other. GANs are trained in an adversarial manner to generate data mimicking some distribution.
Generative Adversarial Networks are composed of two models:
- The first model is called a Generator and it aims to generate new data similar to the expected one. The Generator could be assimilated to a human art forger, which creates fake works of art.
- The second model is named the Discriminator. This model’s goal is to recognize if an input data is ‘real’, belongs to the original dataset, or if it is ‘fake’, generated by a forger. In this scenario, a Discriminator is analogous to an art expert, which tries to detect artworks as truthful or fraud.
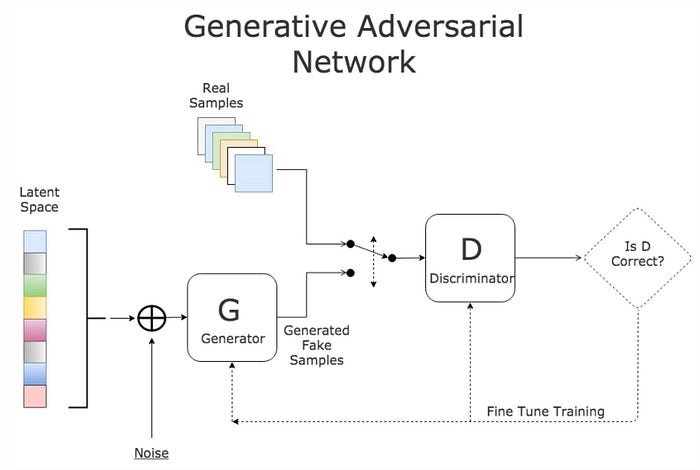
Simple Example
A video that describes GAN.
Assume we want a GAN to learn how to generate left diagonals.
Training:
- Sample a first set containing some examples of fake and real data.
- Train the Discriminative Network on these examples.
- Sample another set containing examples of fake data.
- Train the Generative Network on this set.
- Repeat the steps.